
Applied Statistical Causal Inference in Requirements Engineering: Tutorial Debriefing
27 Oct 2025At the 2025 International Requirements Engineering Conference, I had the chance to host a tutorial titled Applied Statistical Causal Inference in Requirements Engineering. The topic of statistical causal inference is very dear to my heart and sharing some fundamental insights with the requirements engineering community, the community closest to my research, was a wonderful opportunity to teach and learn. In this debriefing, my colleagues and I summarize the main points of the tutorial. For participants, we hope this helps digesting the material. For those that missed the tutorial, the following summary may contain some relevant insights and may even get them interestested to join next time around.
Motivation
As any scientific discipline, the software engineering (SE) research community strives to contribute to the betterment of the target population of our research: software producers and consumers. We will only achieve this betterment if we manage to transfer the knowledge acquired during research into practice. This transferal of knowledge may come in the form of tools, processes, and guidelines for software developers. However, the value of these contributions hinges on the assumption that applying them causes an improvement of the development process, user experience, or other performance metrics. Such a promise requires evidence of causal relationships between an exposure or intervention (i.e., the contributed tool, process or guideline) and an outcome (i.e., performance metrics). A straight-forward approach to obtaining this evidence is via controlled experiments in which a sample of a population is randomly divided into a group exposed to the new tool, process, or guideline, and a control group. However, such randomized control trials may not be legally, ethically, or logistically feasible. In these cases, we need a reliable process for statistical causal inference (SCI) from observational data.
Causal Modelling
Much will be won if researchers in SE adopt one of the simplest techniques in scope of SCI: causal modeling. We can visualize causal assumptions in the form of directed acyclic graphs (DAGs), where nodes represent variables and directed edges represent assumed causal relationships.1 Vice versa, the absence of an edge represents the assumptions that two variables are not directly related. The figure below shows a simple DAG representing the causal assumption that AI-support affects coding performance.
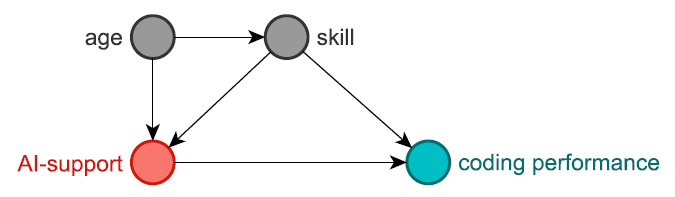
Additionally, the figure encodes the assumption that the skill of a developer both affects their inclination to use AI-support and their overall coding performance. Similarly, age is assumed to affect skill but also the aforementioned inclination.
Do you agree with this DAG? You might not. Based on your assumptions, experience, or prior research, you may find additional variables relevant or you would connect them differently. A DAG always represents a researcher’s understanding of real-world phenomena. But a DAG makes this understanding transparent and captures even complex relationships that may not be easily expressed in a null-hypothesis stated in natural language. Its transparency allows to review, critique, and improve it by proposing the inclusion of new or exclusion of existing variables, and updating the edges between them. Try to think of other variables that you believe or know would affect the effect of AI-support on coding performance. In fact, DAGs encourage challenging them: SCI has methods to determine which one of several potential DAGs reflects the real-world phenomenon better. This way, we can incrementally improve our understanding of these phenomena.
Three Elemental Sources of Bias
Moreover, DAGs expose potential sources of bias. In observational studies, the effect of a treatment of interest (here: AI-support) on an outcome of interest (here: coding performance) may be biased by other variables. This does not happen in true controlled experiments where the treatment is assigned at random. In a DAG, this would mean that no arrow “enters” (i.e., points towards) the treatment. But when you understand how other factors bias this effect of interest, you can take counter measures. There are essentially three different relationships in which a third variable z can interact with an effect of interest of x → y, visualized as the three DAGs below.

These three different types of relationship require different treatment:
- Confounder: If z is a common cause of both x and y (x ← z → y) we must control for it statistically when estimating the effect x → y (where “controlling for” means including the variable in a statistical analysis, for example as a regressor in a linear model). Otherwise, z will bias this effect. This is the classic case of confounding.
- Mediator: If z is located on a pipe (i.e., a causal chain where information flows sequentially from one variable to the next) from x to y (x → z → y) we can control for it. If we do control for z, we distinguish the direct effect (x → y) from the indirect effect through z (x → z → y). If we do not control for z, we obtain the total effect (i.e., combining the direct (x → y) with the indirect (x → z → y) effect). Both are correct, but answer different questions.
- Collider: If z is a common effect of both x and y (x → z ← y) we must not control for it. By default, the effect x → y is unbiased in this case, but controlling for z will introduce a bias. You may know this phenomenon as Berkson’s paradox.2
Handling these relationships is a major aspect of research design. Controlling confounders ensures internal validity, while ignoring colliders makes sure one does not condition on post-treatment variables. Controlling mediators allows isolating the direct effect of a treatment. For example: does a newly proposed testing technique x really improve test coverage y (i.e., the direct effect x → y) or does it rather affect testers’ attention z which in turn produces tests with better coverage (i.e., the indirect effect x → z → y)? Depending on which effect is stronger, a study may conclude either to employ the testing technique or heighten the attention of testers.
Overall Framework
Understanding potential sources of bias enables debiasing a causal effect of interest even when dealing with data from an observational study. The following framework proposed by Julien Siebert3 (derived from the seminal work of Judea Pearl4) includes three steps for SCI:
- Modeling: Formalize your causal assumptions in a DAG.
- Identification: Given the relationships between variables, identify those that you need to statistically control for in order to de-bias the causal effect of interest.
- Estimation: Estimate the causal effect of interest with statistical means (e.g., regression models) while controlling for the previously identified variables.
Adherence to SCI principles will propel our scientific endeavors in SE research beyond limitations of correlational analyses and the constraints of experimentation. Beyond the ability to de-bias a causal effect of interest, SCI principles contribute further benefits to a scientific discipline:
- The transparency of causal assumptions facilitates iterative improvement of empirical evidence. Reviewing, improving, and comparing causal DAGs maps individual pieces of evidence to the continuous improvement of our understanding of SE phenomena.
- The identification of variables potentially biasing an effect of interest informs data collection, i.e., which factors z to record in addition to x and y such that we can control for them in the analysis.
- Causal DAGs facilitate a clearer and more honest discussion of threats to validity. Instead of relying on common practice, threats to internal validity can be connected to variables that bias the effect of interest but could not be collected.
This is a complex topic one should not expect to master in a day. Proper SCI is much more powerful but also takes much more effort than just picking an appropriate null-hypothesis significance test. We hope the tutorial and\or this debriefing inspired you to get into SCI for SE. In case of questions, we are more than happy to support you in learning more about it.
Resources
Finally, find some useful resources to consult when undertaking the journey of learning SCI. The publications of many great authors in the recent years have made SCI fairly accessible to the interested researcher:
- “The Book of Why” by Judea Pearl4 is written for a general audience and masterfully introduces the fundamental ideas, history, and methods of SCI.
- “Statistical Rethinking” by Richard McElreath5 is the extensive text book teaching the craft of SCI in minute detail. On top of being grounded in causal principles, the author adopts a Bayesian perspective to data analysis.
- “A Crash Course in Good and Bad Controls” by Carlos Cinelli and colleagues6 elaborates which variables to control for given a causal DAG. Thanks to several illustrative examples, this is a very accessible and rewarding read.
- “Applications of Statistical Causal Inference in Software Engineering” by Julien Siebert3 summarizes prior work using SCI in SE. This literature study shows that its application is yet limited - meaning that it is the perfect time to get started and join the frontier of SCI in SE.
- “Applying Bayesian Analysis Guidelines to Empirical Software Engineering Data” by Carlo Furia and colleagues7 applies SCI principles in SE research. This is one of the best practical demonstrations of SCI for our field.
- “Causal Models in Requirement Specifications for Machine Learning: A vision” by Hans-Martin Heyn and colleagues8 goes even further and applies SCI principles not only to SE research, but to SE practice as well, underlining their overall potential.
Many more great references could be mentioned here, and we hope that many more great references will be added to the list in the future to help our requirements and software engineering community adopt methods of SCI in our portfolio. For actual application and tooling, we recommend the programming language R and the following packages:
- To draw and evaluate DAGs, we can recommend DAGitty or GGDag.
- To estimate causal effects based on DAGs using a Bayesian perspective, consider following along the above-referenced book “Statistical Rethinking” using the rethinking package. Once having understood the principles, we can recommend switching to brms by Paul Bürkner.
The material from our tutorial remains available under an open source license on GitHub (see: github.com/JulianFrattini/bda4sci). It includes the presentation slides as well as code examples to recreate figures and analyses. Finally, you can find an archived version of this blog post on arXiv at arxiv.org/abs/2511.03875.
specifications for machine learning: A vision. In Proceedings of the 33rd ACM In- ternational Conference on the Foundations of Software Engineering, pages 1402–1405, 2025
-
M. M. Glymour and S. Greenland. Causal diagrams. 2008 ↩
-
J. Berkson. Limitations of the application of fourfold table analysis to hospital data. Biometrics Bulletin, 2(3):47–53, 1946 ↩
-
J. Siebert. Applications of statistical causal inference in software engineering. Information and Software Technology, 159:107198, 2023. doi: 10.1016/j.infsof.2023.107198 ↩ ↩2
-
J. Pearl and D. Mackenzie. The book of why: the new science of cause and effect. Basic books, 2018 ↩ ↩2
-
R. McElreath. Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC, 2018. doi: 10.1201/9781315372495 ↩
-
C. Cinelli, A. Forney, and J. Pearl. A crash course in good and bad controls. Sociological Methods & Research, 53(3):1071–1104, 2024. doi: 10.1177/00491241221099552 ↩
-
C. A. Furia, R. Torkar, and R. Feldt. Applying bayesian analysis guidelines to empirical software engineering data: The case of programming languages and code quality. ACM Transactions on Software Engineering and Methodology (TOSEM), 31 (3):1–38, 2022. doi: 10.1145/3490953 ↩
-
H.-M. Heyn, Y. Mao, R. Weiß, and E. Knauss. Causal models in requirement ↩